Hướng dẫn sử dụng Java Jsoup phân tích HTML
1. Jsoup là gì?
Jsoup là Java HTML Parser. Nói cách khac Jsoup là một thư viện được sử dụng để phân tích tài liệu HTML. Jsoup cung cấp các API dùng để lấy dữ liệu và thao tác dữ liệu từ URL hoặc từ tập tin HTML. Nó sử dụng các phương thức giống với DOM, CSS , JQuery để lấy dữ liệu và thao tác với dữ liệu.

Hãy xem một ví dụ với Jsoup:
HelloJsoup.java
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class HelloJsoup {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}2. Thư viện Jsoup
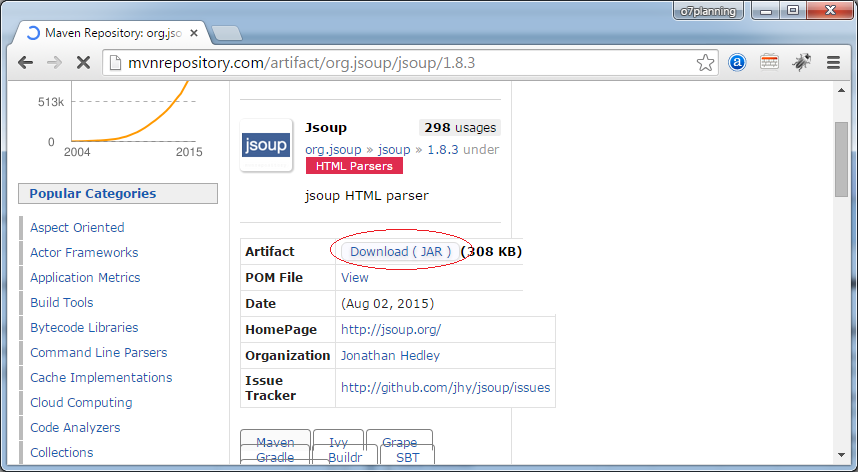
Bạn có thể sử dụng Maven hoặc download thư viện Jsoup dưới dạng file jar.
Với maven:
<!-- http://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
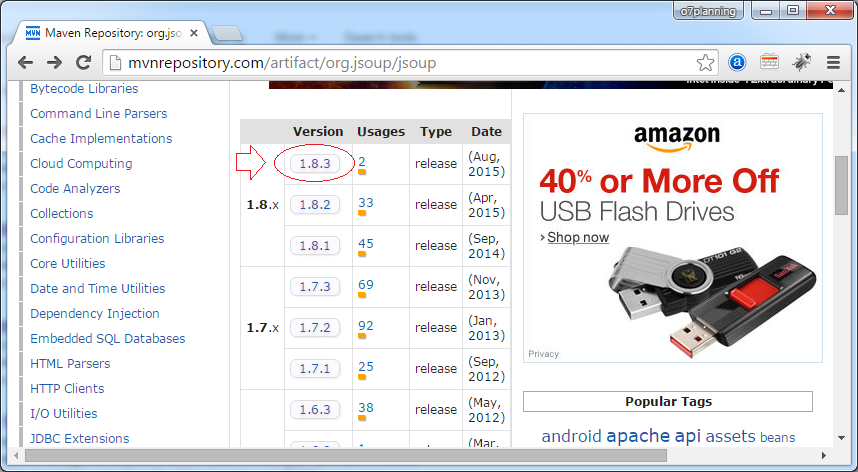
<version>1.8.3</version>
</dependency>Hoặc có thể download:
3. Jsoup API
Jsoup bao gồm nhiều class, tuy nhiên có 3 class quan trọng nhất, bao gồm:
- org.jsoup.Jsoup
- org.jsoup.nodes.Document
- org.jsoup.nodes.Element
- Jsoup.java
Method | Description |
static Connection connect(String url) | Tạo và trả về đối tượng Connection kết nối tới URL. |
static Document parse(File in, String charsetName) | Phân tích một file tài liệu HTML với chỉ định charset . |
static Document parse(File in, String charsetName, String baseUri) | Phân tích file tài liệu HTML với chỉ định charset, và baseUri. |
static Document parse(String html) | Phân tích mã HTML và trả về đối tượng Document. |
static Document parse(String html, String baseUri) | Phân tích mã HTML với baseUri thành đối tượng Document. |
static Document parse(URL url, int timeoutMillis) | Phân tích một URL thành Document. |
static String clean(String bodyHtml, Whitelist whitelist) | Trả về HTML an toàn từ HTML đầu vào, bằng cách phân tích HTML đầu vào và lọc nó qua một danh sách trắng (Whitelist) của các thẻ và các thuộc tính được phép. |
- Document.java
Methods | Description |
Element body() |
Truy cập vào phần tử body của tài liệu HTML |
Charset charset() |
Trả về charset được sử dụng trong tài liệu này
|
void charset(Charset charset) |
Sét charset sử dụng cho tài liệu này.
|
Document clone() |
Tạo một phiên bản copy của tài liệu này, bao gồm copy cả các node con.
|
Element createElement(String tagName) |
Tạo mới một phần tử
|
static Document createShell(String baseUri) |
Tạo một tài liệu (Document) rỗng, thích hợp cho việc thêm các phần tử vào nó.
|
Element head() |
Truy cập vào phần tử head.
|
String location() |
Trả về URL của tài liệu này.
|
String nodeName() |
Trả về node name của node này.
|
Document normalise() |
Normalise the document.
|
String outerHtml() |
Trả về Outer HTML của node này.
|
Document.OutputSettings outputSettings() |
Trả về đối tượng là các thiết lập đầu ra cho tài liệu này.
|
Document outputSettings(Document.OutputSettings outputSettings) |
Sét đặt đầu ra cho tài liệu.
|
Document.QuirksMode quirksMode() | |
Document quirksMode(Document.QuirksMode quirksMode) | |
Element text(String text) |
Sét đặt nội dung văn bản (text) của body của tài liệu này.
|
String title() |
Trả về nội dung tiêu đề của tài liệu.
|
void title(String title) |
Sét đặt nội dung tiêu đề cho tài liệu.
|
boolean updateMetaCharsetElement() |
Trả về true nếu phần tử (element) với thông tin charset trong tài liệu này được cập nhập thay đổi thông qua phương thức Document.charset(Charset). |
void updateMetaCharsetElement(boolean update) |
Sét đặt có hoặc không, phần tử (element) này với thông tin charset được cập nhập thay đổi thông qua phương thức Document.charset(Charset).
|
- Element.java
4. Thao tác với Document
Tạo Documet từ URL
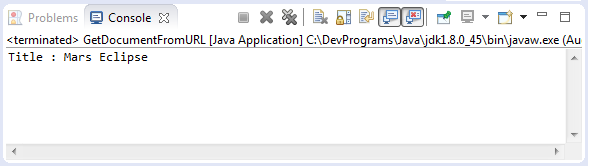
GetDocumentFromURL.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromURL {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}Chạy ví dụ:
Tạo Document từ File
GetDocumentFromFile.java
package org.o7planning.tutorial.jsoup.document;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromFile {
public static void main(String[] args) throws IOException {
File htmlFile = new File("C:/index.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
String title = doc.title();
System.out.println("Title : " + title);
}
}Tạo Document từ String
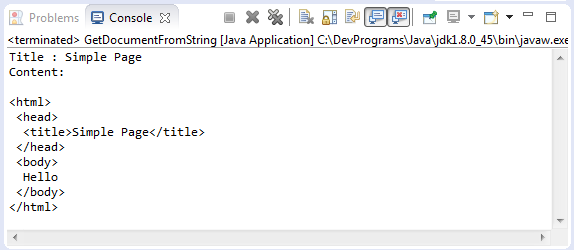
GetDocumentFromString.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromString {
public static void main(String[] args) throws IOException {
String htmlString = "<html><head><title>Simple Page</title></head>"
+ "<body>Hello</body></html>";
Document doc = Jsoup.parse(htmlString);
String title = doc.title();
System.out.println("Title : " + title);
System.out.println("Content:\n");
System.out.println(doc.toString());
}
}Chạy ví dụ:
Phân tích đoạn HTML
Một tài liệu HTML đầy đủ bao gồm cả Header và Body, đôi khi bạn cũng cần phân tích một đoạn HTML. Và bạn có thể lấy ra một tài liệu HTML đầy đủ bao gồm cả header & body. Hãy xem ví dụ:
ParsingBodyFragment.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParsingBodyFragment {
public static void main(String[] args) throws IOException {
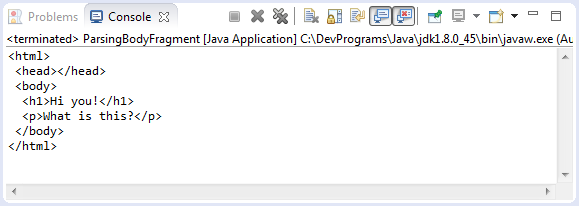
String htmlFragment = "<h1>Hi you!</h1><p>What is this?</p>";
Document doc = Jsoup.parseBodyFragment(htmlFragment);
String fullHtml = doc.html();
System.out.println(fullHtml);
}
}Chạy ví dụ:
5. Các phương thức DOM
Jsoup có một vài phương thức gần giống với các phương thức trong mô hình DOM (Một mô hình để phân tích tài liệu XML)
Phương thức | Mô tả |
Element getElementById(String id) | Tìm một phần tử cho bởi ID, bao gồm hoặc bên dưới phần tử này. |
Elements getElementsByTag(String tag) | Tìm các phần tử, bao gồm và cả đệ quy dưới phần tử này, với tên thẻ chỉ định. |
Elements getElementsByClass(String className) | Tìm phần tử có classNam cho bởi tham số, bao gồm hoặc dưới phần tử này. |
Elements getElementsByAttribute(String key) | Tìm kiếm các phần tử có thuộc tính cho bởi tham số, không phân biệt chữ hoa chữ thường. |
Elements siblingElements() | Trả về các phần tử anh em với phần tử hiện tại. |
Element firstElementSibling() | Trả về phần tử anh em đầu tiên của phần tử hiện tại. |
Element lastElementSibling() | Trả về phần tử anh em cuối cùng của phần tử hiện tại. |
...... | |
Các phương thức lấy dữ liệu trên Element.
Phương thức | Mô tả |
String attr(String key) | Trả về giá trị thuộc tính cho bởi key của phần tử này. |
void attr(String key, String value) | Sét giá trị thuộc tính. Nếu thuộc tính đã tồn tại, nó sẽ bị thay thế. |
String id() | Trả về thuộc tính ID, nếu có, hoặc trả về string rỗng nếu không có. |
String className() | Trả về chuỗi chữ giá trị của thuộc tính "class", nó có thể chứa nhiều class name, ngăn cách bởi khoảng trắng. (Ví dụ <div class="header gray"> trả về "header gray") |
Set<String> classNames() | Trả về tất cả các class names. Ví dụ <div class="header gray">, trả về tập hợp 2 phần tử "header" và "gray". Chú ý, sửa đổi trên tập hợp này không làm thay đổi thuộc tính của phần tử. Muốn thay đổi sử dụng phương thức classNames(java.util.Set). |
String text() | Trả về một văn bản kết hợp text của nó và tất cả các text của tất cả các phần tử con. |
void text(String value) | Sét text cho phần tử này. |
String html() | Trả về String các HTML bên trong thẻ này. Ví dụ <div><p>a</p> trả về <p>a</p>. (Node.outerHtml() sẽ trả về <div><p>a</p></div>.) |
void html(String value) | Sét Html bên trong phần tử này. Xóa hết các HTML sẵn có bên trong. |
Tag tag() | Trả về Tag cho phần tử này. |
String tagName() | Trả về tên thẻ của phần tử này. Ví dụ div. |
...... | |
Các phương thức vận dụng HTML:
Methods | Description |
Element append(String html) | Nối thêm HTML vào trong phần tử này. Html được cung cấp sẽ được phân tích, và các node sẽ được nối vào phía cuối tập các node con của phần tử này. |
Element prepend(String html) | Nối thêm HTML vào phần tử này. Html được cung cấp sẽ được phân tích, và các node sẽ được nối vào phía trước tập các node con của phẩn tử này. |
Element appendText(String text) | Tạo và nối một TextNode mới vào phần tử này. |
Element prependText(String text) | Tạo và nối một TextNode mới vào phía trước tập các node con của phần tử này. |
Element appendElement(String tagName) | Tạo một phần tử mới cho bởi tag name. Và nối nó vào như phần tử con ở cuối cùng. |
Element prependElement(String tagName) | Tạo mới một phần tử bởi tag name, và nối nó vào như phần tử con đầu tiên. |
Element html(String value) | Sét đặt html bên trong phần tử này. Xóa hết Html bên trong sẵn có. |
...... | |
Ví dụ sử dụng các phương thức DOM, phân tích một tài liệu HTML ghi ra các thông tin trong thẻ form.
register.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Register</title>
</head>
<body>
<form id="registerForm" action="doRegister" method="post">
<table>
<tr>
<td>User Name</td>
<td><input type="text" name="userName" value="Tom" /></td>
</tr>
<tr>
<td>Password</td>
<td><input type="password" name="password" value="Tom001" /></td>
</tr>
<tr>
<td>Email</td>
<td><input type="email" name="email" value="theEmail@gmail.com" /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" name="submit" value="Submit" /></td>
</tr>
</table>
</form>
</body>
</html>ReadHtmlForm.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
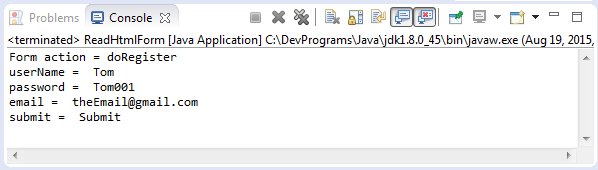
public class ReadHtmlForm {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.parse(new File("files/register.html"), "utf-8");
Element form = doc.getElementById("registerForm");
System.out.println("Form action = "+ form.attr("action"));
Elements inputElements = form.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println(key + " = " + value);
}
}
}Chạy ví dụ:
GetAllLinks.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
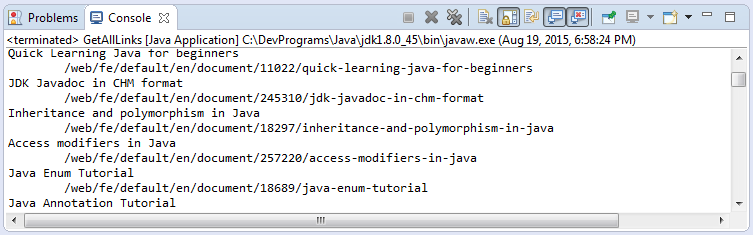
public class GetAllLinks {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://o7planning.org").get();
// Elements extends ArrayList<Element>.
Elements aElements = doc.getElementsByTag("a");
for (Element aElement : aElements) {
String href = aElement.attr("href");
String text = aElement.text();
System.out.println(text);
System.out.println("\t" + href);
}
}
}Chạy ví dụ:
6. Các phương thức tương tự Css, jQuery
Bạn muốn tìm kiếm hoặc vận dụng các phần tử sử dụng ngữ pháp giống CSS hoặc jQuery?
JSoup cung cấp cho bạn một vài phương thức để làm việc này:
- Element.select(String selector)
- Elements.select(String selector)
Ví dụ:
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// Phần tử a với thuộc tính href
Elements links = doc.select("a[href]");
// img với thuộc tính src kết thúc bởi .png
Elements pngs = doc.select("img[src$=.png]");
// div với class=masthead
Element masthead = doc.select("div.masthead").first();
// Phần tử a ngay sau h3.
Elements resultLinks = doc.select("h3.r > a");Các phần tử JSoup hỗ trợ bạn cú pháp giống với CSS (hoặc JQuery) giúp bạn tìm kiếm các phần tử phù hợp. Những hỗ trợ như vậy là rất mạnh mẽ. Các phương thức lựa chọn có sẵn trong lớp Document, Element hoặc Elements.
Tổng quan về Selector (Bộ lựa chọn).
Selector | Mô tả |
tagname | Tìm kiếm các phần tử theo tên thẻ. Ví dụ: a |
ns|tag | Tìm kiếm các phần tử theo tên thẻ trong một không gian tên (namespace), ví dụ fb|name nghĩa là tìm các phần tử <fb:name> |
#id | Tìm kiếm phần tử theo ID, ví dụ #logo |
.class: | Tìm kiếm các phần tử theo tên class, ví dụ .masthead |
[attribute] | Các phần tử với thuộc tính, ví dụ [href] |
[^attr] | Các phần tử với thuộc tính bắt đầu bởi, ví dụ [^data-] tìm kiếm các phần tử với thuộc tính bắt đầu bởi data- |
[attr=value] | Các phần tử với giá trị thuộc tính, ví dụ [width=500] (Cũng có thể sử dụng dấu nháy kép) |
[attr^=value], [attr$=value], [attr*=value] | Các phần tử với giá trị thuộc tính bắt đầu, kết thúc bởi, hoặc chứa giá trị, ví dụ [href*=/path/] |
[attr~=regex] | Các phần tử với giá trị khớp với biểu thức chính quy, ví dụ img[src~=(?i)\.(png|jpe?g)] |
* | Tất cả các phần tử, ví dụ * |
Selector kết hợp
Selector | Mô tả |
el#id | Phần tử với ID, ví dụ div#logo |
el.class | Các phần tử với class, ví dụ div.masthead |
el[attr] | Các phần tử với thuộc tính, ví dụ a[href] |
Kết hợp bất kỳ | Ví dụ a[href].highlight |
ancestor child | (Phần tử tổ tiên- và hậu duệ) Các phần tử hậu duệ của một phần tử, ví dụ. .body p tìm kiếm các phần tử p bất kỳ là hậu duệ của phần tử có thuộc tính class = "body". |
parent > child | Các phần tử con trực tiếp của phần tử cha, ví dụ div.content > p tìm kiếm các phần tử p là con trực tiếp của div có class ='content'; và body > * tìm kiếm các phần tử con trực tiếp của thẻ body. |
siblingA + siblingB | Tìm kiếm phần tử anh em B ngay phía trước của phần tử A, ví dụ div.head + div |
siblingA ~ siblingX | Tìm kiếm các phần tử anh em X trước phần tử A, ví dụ h1 ~ p |
el, el, el | Nhóm nhiều Selector, tìm kiếm các phần tử khớp với một trong những Selector; ví dụ div.masthead, div.logo |
Pseudo selectors
Selector | Mô tả |
:lt(n) | Tìm kiếm các phần tử có chỉ số anh em (vị trí trong cây DOM quan hệ với phần tử cha của nó) nhỏ hơn n; ví dụ td:lt(3) |
:gt(n) | Tìm kiếm các phần tử có chỉ số anh em lớn hơn n, ví dụ div p:gt(2) |
:eq(n) | find elements whose sibling index is equal to n; e.g. form input:eq(1) |
:has(seletor) | Tìm kiếm các phần tử chứa các phần tử khớp với selector; ví dụ div:has(p) |
:not(selector) | Tìm kiếm các phần tử không khớp với selector; ví dụ div:not(.logo) |
:contains(text) | Tìm kiếm các phần tử chứa đoạn text đã cho. Tìm kiếm không phân biệt chữ hoa chữ thường; ví dụ p:contains(jsoup) |
:containsOwn(text) | Tìm kiếm các phần tử trực tiếp chứa đoạn text đã cho |
:matches(regex) | Tìm kiếm các phần tử mà text khớp với biểu thức chính quy chỉ định; ví dụ div:matches((?i)login) |
:matchesOwn(regex) | Tìm kiếm các phần tử mà text của nó khớp với biểu thức chính quy chỉ định. |
Chú ý: Cách đánh chỉ số pseudo bắt đầu từ 0, phần tử đầu tiên có chỉ số 0, phần tử thứ 2 có chỉ số 1,.. | |
QueryLinks.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class QueryLinks {
public static void main(String[] args) throws IOException {
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// Truy vấn các phần tử a mà href chứa /document/
String cssQuery = "a[href*=/document/]";
Elements elements= doc.select(cssQuery);
Iterator<Element> iterator = elements.iterator();
while(iterator.hasNext()) {
Element e = iterator.next();
System.out.println(e.attr("href"));
}
}
}Kết quả chạy ví dụ:
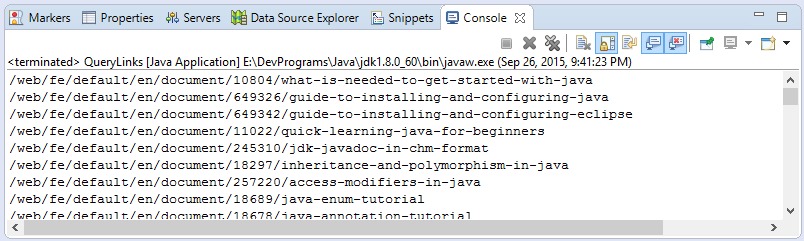
document.html
<html>
<head>
<title>Jsoup Example</title>
</head>
<body>
<h1>Java Tutorial For Beginners</h1>
<br>
<div id="content">
Content ....
</div>
<div class="related-container">
<h3>Related Documents</h3>
<a href="http://o7planning.org/web/fe/default/en/document/649342/guide-to-installing-and-configuring-eclipse">
Guide to Installing and Configuring Eclipse
</a>
<a href="http://o7planning.org/web/fe/default/en/document/649326/guide-to-installing-and-configuring-java">
Guide to Installing and Configuring Java
</a>
<a href="http://o7planning.org/web/fe/default/en/document/245310/jdk-javadoc-in-chm-format">
Jdk Javadoc in chm format
</a>
</div>
</body>
</html>SelectorDemo1.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SelectorDemo1 {
public static void main(String[] args) throws IOException {
File htmlFile = new File("document.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
// Phần tử <div> đầu tiên có class ="related-container".
Element div = doc.select("div.related-container").first();
// Danh sách các phần tử <h3>, con trực tiếp của phần tử hiện tại.
Elements h3Elements = div.select("> h3");
// Lấy phần tử h3 đầu tiên
Element h3 = h3Elements.first();
System.out.println(h3.text());
// Danh sách các phần tử <a> hậu duệ của phần tử hiện tại.
Elements aElements = div.select("a");
// Truy vấn trong danh sách phần tử hiện tại.
// Các phần tử mà href có chứa từ installing.
Elements aEclipses = aElements.select("[href*=Installing]");
Iterator<Element> iterator = aEclipses.iterator();
while (iterator.hasNext()) {
Element a = iterator.next();
System.out.println("Document: "+ a.text());
}
}
}Kết quả chạy ví dụ:
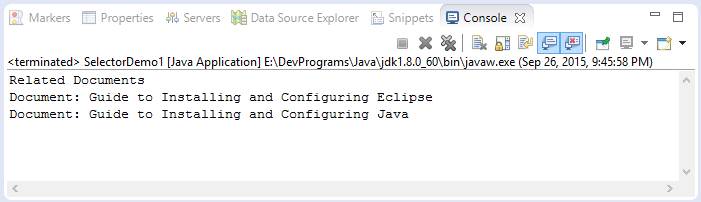
Java API cho HTML & XML
- Sử dụng Java SAX phân tích tài liệu XML
- Phân tích XML bằng cách sử dụng mô hình DOM trong Java
- Hướng dẫn và ví dụ Java JAXB
- Hướng dẫn sử dụng Java JDOM2 phân tích tài liệu XML
- Hướng dẫn sử dụng Java Jsoup phân tích HTML
- Hướng dẫn và ví dụ Java XStream
- Ví dụ Java đơn giản bắt đầu với DOM
Show More
Các thư viện mã nguồn mở Java
- Hướng dẫn và ví dụ Java JSON Processing API (JSONP)
- Hướng dẫn sử dụng Scribe OAuth Java API với Google OAuth 2
- Lấy thông tin phần cứng máy tính trong ứng dụng Java
- Restfb Java API cho Facebook
- Tạo Credentials cho Google Drive API
- Hướng dẫn sử dụng Java JDOM2 phân tích tài liệu XML
- Hướng dẫn và ví dụ Java XStream
- Hướng dẫn sử dụng Java Jsoup phân tích HTML
- Lấy thông tin địa lý dựa trên địa chỉ IP sử dụng GeoIP2 Java API
- Đọc Ghi file excel trong Java sử dụng Apache POI
- Khám phá Facebook Graph API
- Java Sejda WebP ImageIO chuyển đổi các định dạng ảnh sang WEBP
- Java JAVE Chuyển đổi audio và video sang định dạng mp3
- Thao tác với tập tin và thư mục trên Google Drive sử dụng Java
Show More
