Hướng dẫn và ví dụ Java FilterReader
1. FilterReader
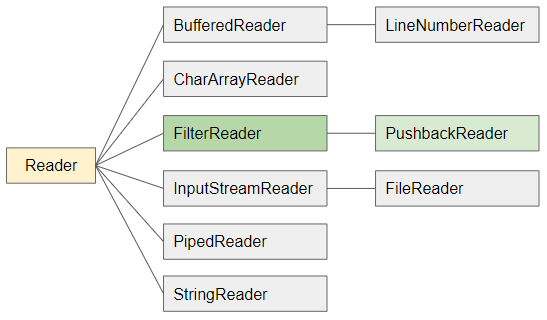
FilterReader là một lớp con trừu tượng của lớp Reader. Nó là lớp cơ sở để tạo ra các lớp con để đọc một cách có chọn lọc các ký tự theo yêu cầu. Chẳng hạn bạn muốn đọc một văn bản HTML, và bỏ qua các thẻ (tag). Bạn cần viết một lớp con của FilterReader, bạn không thể sử dụng trực tiếp FilterReader vì nó là một lớp trừu tượng (abstract class).
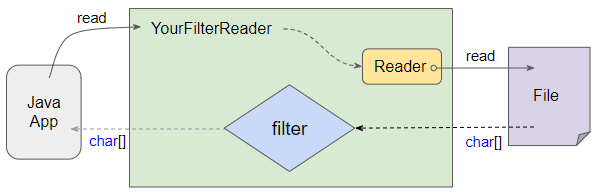
FilterReader không trực tiếp đọc dữ liệu từ nguồn gốc (chẳng hạn file) mà nó quản lý một Reader khác chịu trách nhiệm đọc dữ liệu từ nguồn gốc. FilterReader xử lý một cách có chọn lọc các dữ liệu có được từ Reader mà nó quản lý.
Nhìn vào mã nguồn của lớp FilterReader cho thấy: Tất cả các phương thức mà nó thừa kế từ lớp cha đã được ghi đè (override) để hoạt động như một người uỷ quyền của đối tượng Reader mà nó quản lý:
FilterReader class
package java.io;
public abstract class FilterReader extends Reader {
protected Reader in;
protected FilterReader(Reader in) {
super(in);
this.in = in;
}
public int read() throws IOException {
return in.read();
}
public int read(char cbuf[], int off, int len) throws IOException {
return in.read(cbuf, off, len);
}
public long skip(long n) throws IOException {
return in.skip(n);
}
public boolean ready() throws IOException {
return in.ready();
}
public boolean markSupported() {
return in.markSupported();
}
public void mark(int readAheadLimit) throws IOException {
in.mark(readAheadLimit);
}
public void reset() throws IOException {
in.reset();
}
public void close() throws IOException {
in.close();
}
}FilterReader constructors
protected FilterReader(Reader in)2. Examples
Ví dụ: Viết một lớp con của FilterReader để đọc văn bản HTML nhưng bỏ qua các thẻ (tag).
RemoveHtmlTagReader.java
package org.o7planning.filterreader.ex;
import java.io.FilterReader;
import java.io.IOException;
import java.io.Reader;
public class RemoveHtmlTagReader extends FilterReader {
private boolean intag = false;
public RemoveHtmlTagReader(Reader in) {
super(in);
}
// We override this method.
// The principle will be:
// Read only characters outside of the tags.
@Override
public int read(char[] buf, int from, int len) throws IOException {
int charCount = 0;
while (charCount == 0) {
charCount = super.read(buf, from, len);
if (charCount == -1) {
// Ends of
return -1;
}
int last = from;
for (int i = from; i < from + charCount; i++) {
// If not in tag
if (!this.intag) {
if (buf[i] == '<') {
this.intag = true;
} else {
buf[last++] = buf[i];
}
} else if (buf[i] == '>') {
this.intag = false;
}
}
charCount = last - from;
}
return charCount;
}
// Also need to override this method.
@Override
public int read() throws IOException {
char[] buf = new char[1];
int result = read(buf, 0, 1);
if (result == -1) {
return -1;
} else {
return (int) buf[0];
}
}
}RemoveHtmlTagTest.java
package org.o7planning.filterreader.ex;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.Reader;
import java.io.StringReader;
public class RemoveHtmlTagTest {
public static void main(String[] args) throws IOException {
// Create a Reader.
Reader in = new StringReader("<h1>Hello \n <b>World</b><h1>");
RemoveHtmlTagReader filterReader = new RemoveHtmlTagReader(in);
BufferedReader br = new BufferedReader(filterReader);
String s = null;
while ((s = br.readLine()) != null) {
System.out.println(s);
}
br.close();
}
}Output:
Hello
WorldCác hướng dẫn Java IO
- Hướng dẫn và ví dụ Java CharArrayWriter
- Hướng dẫn và ví dụ Java FilterReader
- Hướng dẫn và ví dụ Java FilterWriter
- Hướng dẫn và ví dụ Java PrintStream
- Hướng dẫn và ví dụ Java BufferedReader
- Hướng dẫn và ví dụ Java BufferedWriter
- Hướng dẫn và ví dụ Java StringReader
- Hướng dẫn và ví dụ Java StringWriter
- Hướng dẫn và ví dụ Java PipedReader
- Hướng dẫn và ví dụ Java LineNumberReader
- Hướng dẫn và ví dụ Java PushbackReader
- Hướng dẫn và ví dụ Java PrintWriter
- Hướng dẫn sử dụng luồng vào ra nhị phân trong Java
- Hướng dẫn sử dụng luồng vào ra ký tự trong Java
- Hướng dẫn và ví dụ Java BufferedOutputStream
- Hướng dẫn và ví dụ Java ByteArrayOutputStream
- Hướng dẫn và ví dụ Java DataOutputStream
- Hướng dẫn và ví dụ Java PipedInputStream
- Hướng dẫn và ví dụ Java OutputStream
- Hướng dẫn và ví dụ Java ObjectOutputStream
- Hướng dẫn và ví dụ Java PushbackInputStream
- Hướng dẫn và ví dụ Java SequenceInputStream
- Hướng dẫn và ví dụ Java BufferedInputStream
- Hướng dẫn và ví dụ Java Reader
- Hướng dẫn và ví dụ Java Writer
- Hướng dẫn và ví dụ Java FileReader
- Hướng dẫn và ví dụ Java FileWriter
- Hướng dẫn và ví dụ Java CharArrayReader
- Hướng dẫn và ví dụ Java ByteArrayInputStream
- Hướng dẫn và ví dụ Java DataInputStream
- Hướng dẫn và ví dụ Java ObjectInputStream
- Hướng dẫn và ví dụ Java InputStreamReader
- Hướng dẫn và ví dụ Java OutputStreamWriter
- Hướng dẫn và ví dụ Java InputStream
- Hướng dẫn và ví dụ Java FileInputStream
Show More
- Hướng dẫn lập trình Java Servlet/JSP
- Các hướng dẫn Java New IO
- Các hướng dẫn Spring Cloud
- Các hướng dẫn Java Oracle ADF
- Các hướng dẫn Java Collections Framework
- Java cơ bản
- Các hướng dẫn Java Date Time
- Các thư viện mã nguồn mở Java
- Các hướng dẫn Java Web Services
- Các hướng dẫn Struts2 Framework
- Các hướng dẫn Spring Boot
